Gemini 2.5 Flash آمد: AI گوگل که "فکر" میکند! (استدلال هیبریدی)
گوگل Gemini 2.5 Flash را معرفی کرد! مدل AI هیبریدی با استدلال قابل کنترل و بودجه تفکر برای تعادل سرعت/هزینه/کیفیت. جزئیات کامل در وبلاگ های ورت! همین الان بخوانید.

مسابقه نفسگیر توسعه هوش مصنوعی (AI) وارد مرحله جدیدی شده است. دیگر تنها سرعت و دقت در ارائه پاسخهای آنی مطرح نیست؛ تمرکز به طور فزایندهای به سمت توانایی استدلال (Reasoning)، درک عمیق تر مسائل پیچیده و توانایی "فکر کردن" قبل از ارائه پاسخ، معطوف شده است. در این میان، گوگل به عنوان یکی از پیشگامان اصلی این عرصه، با خانواده مدلهای قدرتمند Gemini خود، همواره به دنبال نوآوری بوده است.
حالا، گوگل با معرفی نسخه پیشنمایش Gemini 2.5 Flash، گامی بلند و هیجانانگیز در این مسیر برداشته است. این مدل جدید که بر پایه محبوبیت نسخه قبلی خود یعنی 2.0 Flash (معروف به سرعت و هزینه بهینه) ساخته شده، یک ارتقاء اساسی در قابلیتهای استدلال را به ارمغان میآورد، در حالی که همچنان بر سرعت و مقرونبهصرفه بودن تمرکز دارد. اما شگفتانگیزتر از همه، معرفی قابلیتی نوآورانه به نام "استدلال هیبریدی" است که به توسعهدهندگان اجازه میدهد کنترل بیسابقهای بر فرآیند تفکر هوش مصنوعی داشته باشند! در این مقاله جامع در های ورت (hiwert.com)، به بررسی دقیق Gemini 2.5 Flash، قابلیت منحصربهفرد استدلال قابل کنترل آن، عملکرد، نحوه دسترسی و پیامدهای این پیشرفت مهم برای آینده هوش مصنوعی خواهیم پرداخت.
Gemini 2.5 Flash: میراث دار سرعت و کارایی، مجهز به قدرت استدلا
مدل های "Flash" در خانواده Gemini گوگل، همواره به عنوان گزینه هایی شناخته شده اند که تعادل فوق العاده ای بین سرعت پاسخ دهی و هزینه محاسباتی ارائه میدهند. این ویژگی، آنها را به انتخابی محبوب برای توسعه دهندگانی تبدیل کرده که نیاز به یک مدل هوش مصنوعی سریع و کارآمد برای حجم بالایی از درخواستها دارند.
Gemini 2.5 Flash نیز بر همین اساس ساخته شده، اما یک جهش کیفی بزرگ را تجربه کرده است: افزودن قابلیت های استدلال پیشرفته. گوگل ادعا میکند که این مدل جدید، نسبت عملکرد به هزینه شگفت انگیزی دارد و آن را در مرز پارتو (Pareto Frontier) قرار میدهد؛ نقطهای که در آن نمیتوان یک معیار (مثلاً کیفیت) را بدون قربانی کردن معیار دیگری (مثلاً هزینه یا سرعت) بهبود بخشید.
این مدل جدید از دو روز پیش (۱۷ آوریل ۲۰۲۵) به صورت پیشنمایش (Preview) در دسترس توسعهدهندگان از طریق Gemini API (در پلتفرم های Google AI Studio و Vertex AI) و همچنین برای عموم کاربران در اپلیکیشن Gemini قرار گرفته است.
"مدلهای متفکر" گوگل: استدلال در عمل چگونه اتفاق میافتد؟
اما منظور از "قابلیت استدلال" یا "تفکر" در مدل های جدید Gemini 2.5 چیست؟ برخلاف مدل های سنتی تر که سعی میکنند بلافاصله پس از دریافت دستور (Prompt)، پاسخی را تولید کنند، مدل های متفکر Gemini 2.5 میتوانند یک فرآیند داخلی "تفکر" را قبل از ارائه خروجی نهایی انجام دهند.
وبلاگ رسمی گوگل (Google Blog) در تاریخ ۱۷ آوریل ۲۰۲۵ جزئیات این فرآیند را اینگونه شرح میدهد:
- درک عمیق تر دستور: مدل به جای پاسخدهی سریع، ابتدا زمانی را صرف تحلیل و درک بهتر نیت و پیچیدگیهای دستور کاربر میکند.
- شکستن وظایف پیچیده: اگر دستور نیازمند چندین مرحله یا جنبههای مختلف باشد، مدل آن را به مراحل کوچکتر و قابل مدیریتتر تقسیم میکند.
- برنامهریزی پاسخ: مدل قبل از شروع به تولید متن یا کد، یک برنامه یا طرح کلی برای پاسخ خود ایجاد میکند.
این فرآیند "تفکر" به خصوص در وظایف پیچیده ای که نیازمند استدلال چند مرحله ای هستند (مانند حل مسائل ریاضی دشوار، تحلیل سوالات تحقیقاتی عمیق، یا نوشتن کدهای پیچیده) بسیار مؤثر است و به مدل اجازه میدهد تا به پاسخ های دقیق تر، کامل تر و با ساختار منطقی تری دست یابد. این قابلیت نشان دهنده بلوغ بیشتر مدل های زبانی بزرگ و حرکت آنها به سمت توانایی های شناختی بالاتر است.
استدلال هیبریدی: کنترل روشن/خاموش کردن "تفکر" AI!
شاید نوآورانهترین جنبه Gemini 2.5 Flash، معرفی مفهوم "استدلال هیبریدی" (Hybrid Reasoning) باشد. گوگل این مدل را اولین مدل استدلالگر کاملاً هیبریدی خود مینامد. اما هیبریدی به چه معناست؟
به زبان ساده، گوگل کنترل "کلید روشن/خاموش تفکر" این مدل را به دست توسعه دهندگان داده است! آنها میتوانند بر اساس نیاز اپلیکیشن یا مورد استفاده خود، تصمیم بگیرند که آیا مدل قبل از پاسخ دادن "فکر" کند یا خیر.
- تفکر روشن (Thinking On): در این حالت (که حالت پیشفرض است)، مدل از قابلیتهای استدلال خود برای ارائه پاسخهای با کیفیتتر و دقیقتر برای وظایف پیچیده استفاده میکند.
- تفکر خاموش (Thinking Off): توسعهدهندگان میتوانند با خاموش کردن حالت تفکر، مدل را وادار کنند تا مانند نسل قبلی (2.0 Flash) بلافاصله پاسخ تولید کند. این حالت، کمترین هزینه و کمترین تأخیر (Latency) را به همراه دارد. نکته جالب اینجاست که گوگل ادعا میکند حتی در حالت تفکر خاموش نیز، عملکرد Gemini 2.5 Flash نسبت به 2.0 Flash بهبود یافته است! این یعنی شما میتوانید سرعت بالای نسل قبل را حفظ کنید و در عین حال از پیشرفتهای پایه مدل جدید بهرهمند شوید.
این قابلیت هیبریدی، انعطافپذیری بیسابقهای را در اختیار توسعهدهندگان قرار میدهد تا رفتار مدل را دقیقاً مطابق با نیاز خود تنظیم کنند.
بودجه تفکر (Thinking Budget): مدیریت هوشمندانه هزینه، سرعت و کیفیت
گوگل پا را از صرفاً روشن/خاموش کردن تفکر فراتر گذاشته و ابزار کنترلی دقیقتری را نیز معرفی کرده است: "بودجه تفکر" (Thinking Budget).
- مفهوم بودجه تفکر: توسعهدهندگان میتوانند یک حد بالا (سقف) برای میزان محاسباتی که مدل مجاز است در فاز "تفکر" خود انجام دهد، تعیین کنند. این بودجه بر حسب تعداد توکنها (واحدهای پردازش متن در مدلهای زبانی) اندازهگیری میشود. برای Gemini 2.5 Flash، این بودجه میتواند از ۰ (حالت تفکر خاموش) تا ۲۴,۵۷۶ توکن متغیر باشد.
- کنترل دقیق: این تنظیم از طریق یک پارامتر در API یا یک اسلایدر در محیطهای Google AI Studio و Vertex AI قابل کنترل است.
- تعادل سهگانه: بودجه تفکر به توسعه دهندگان اجازه میدهد تا تعادل دقیق بین سه فاکتور حیاتی کیفیت، هزینه و تأخیر را پیدا کنند:
- بودجه بالاتر: به مدل اجازه میدهد بیشتر "فکر" کند، استدلال عمیقتری انجام دهد و در نتیجه کیفیت پاسخ برای وظایف پیچیده افزایش یابد (اما هزینه و تأخیر نیز ممکن است بیشتر شود).
- بودجه پایین تر (یا صفر): هزینه و تأخیر را به حداقل میرساند، اما ممکن است کیفیت پاسخ برای وظایف خیلی پیچیده به اندازه حالت بودجه بالا نباشد (اگرچه همچنان از 2.0 Flash بهتر است).
- تصمیمگیری هوشمند مدل: نکته مهم این است که مدل طوری آموزش دیده که نیاز به تفکر را بر اساس پیچیدگی دستور درک کند. بنابراین، حتی اگر بودجه بالایی تعیین کنید، مدل لزوماً از تمام آن بودجه استفاده نخواهد کرد مگر اینکه واقعاً لازم باشد. این باعث میشود استفاده از منابع بهینه باشد.
این سطح از کنترل دانهریز (Fine-grained control) بر فرآیند داخلی مدل، گامی بسیار مهم در جهت ساخت ابزارهای هوش مصنوعی عملیتر و قابل تنظیمتر برای کاربردهای دنیای واقعی است.

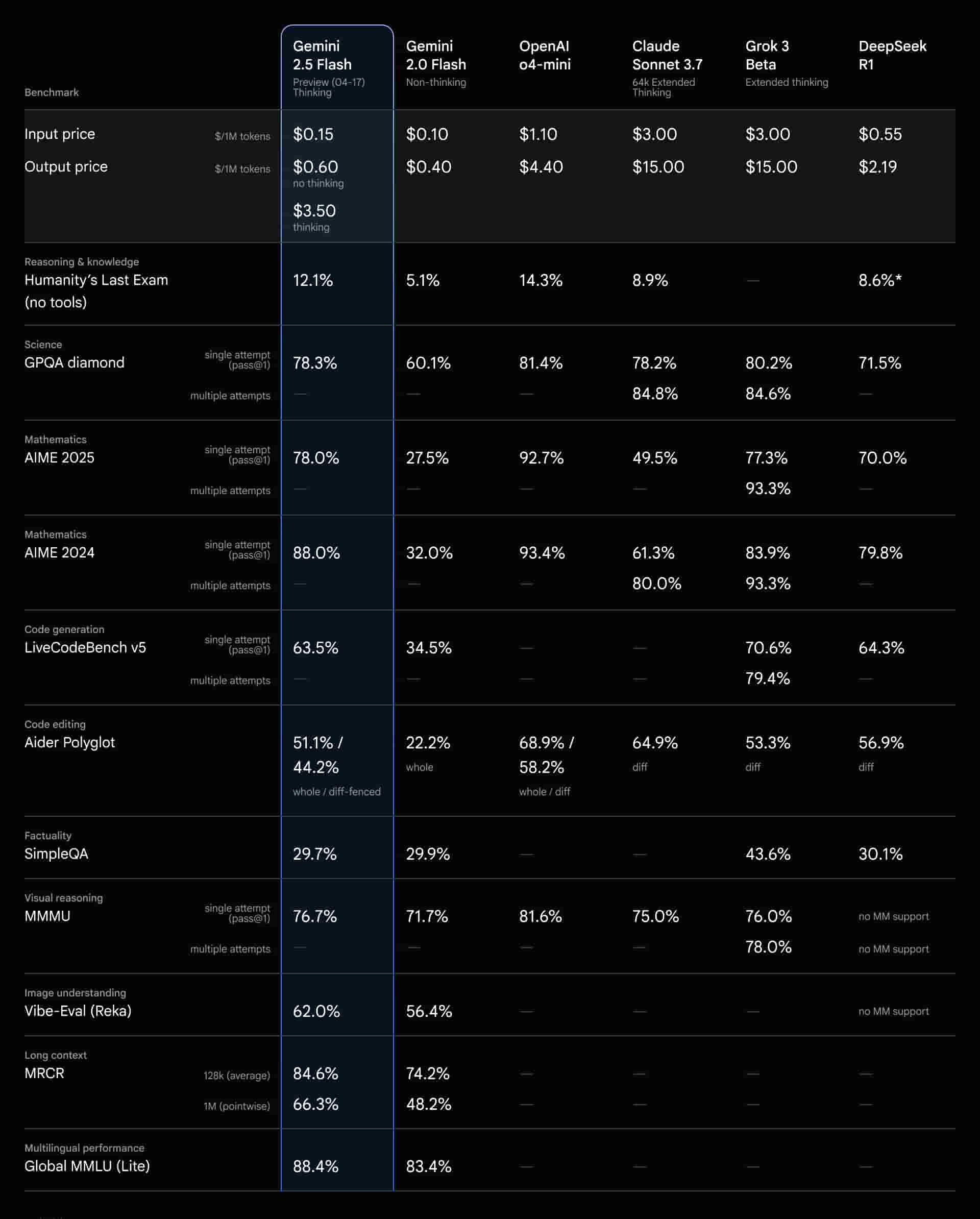
نگاهی به عملکرد: Gemini 2.5 Flash در آزمونهای سخت
گوگل برای نشان دادن قدرت استدلال Gemini 2.5 Flash، به عملکرد آن در پلتفرم معتبر LMArena و در بخش "دستورات سخت" (Hard Prompts) اشاره کرده است. بر اساس ادعای گوگل، 2.5 Flash در این آزمونهای چالشبرانگیز، عملکردی بسیار قوی داشته و تنها پس از مدل قدرتمندتر Gemini 2.5 Pro قرار گرفته است. این نتیجه نشان میدهد که قابلیت استدلال این مدل "Flash"، بسیار فراتر از مدلهای همرده قبلی خود است و میتواند از پس وظایف پیچیده به خوبی برآید.
دسترسی گسترده و ادغام با اکوسیستم گوگل
گوگل دسترسی به Gemini 2.5 Flash را به سرعت فراهم کرده است:
- برای توسعهدهندگان: از طریق Gemini API در Google AI Studio و پلتفرم ابری Vertex AI در دسترس است تا بتوانند بلافاصله شروع به ساخت و آزمایش اپلیکیشنهای خود با این مدل جدید کنند.
- برای کاربران نهایی: نکته جالب توجه این است که Gemini 2.5 Flash همزمان در اپلیکیشن Gemini نیز برای همه کاربران فعال شده است. این یعنی میلیونها کاربر عادی نیز میتوانند از قابلیتهای استدلال بهبود یافته این مدل بهرهمند شوند.
- همراه با ویژگیهای جدید: گوگل همچنین اشاره کرده که 2.5 Flash با ویژگیهای جدیدی مانند Canvas (که یک فضای تعاملی برای کار روی اسناد و کدها توصیف شده - شبیه به ایدههایی که در ابزارهای رقبا دیدهایم) قابل استفاده است، که نشاندهنده تلاش گوگل برای ایجاد یک اکوسیستم یکپارچه و قدرتمند است.
پیامدها و فرصتهای جدید با Gemini 2.5 Flash
معرفی این مدل جدید با قابلیت استدلال قابل کنترل، پیامدهای مهمی برای افراد مختلف دارد:
- برای توسعهدهندگان: انعطافپذیری بینظیر برای بهینهسازی هزینه، سرعت و کیفیت بر اساس نیاز هر اپلیکیشن. توانایی ساخت برنامههایی که قادر به حل مسائل پیچیدهتر هستند، بدون نیاز به استفاده از مدلهای گرانقیمتتر Pro یا Ultra.
- برای کاربران: دریافت پاسخهای دقیقتر و کاملتر به سوالات پیچیده در اپلیکیشن Gemini. تجربه کاربری بهتر در تعامل با هوش مصنوعی، به خصوص در کارهای خلاقانه یا تحلیلی با ابزارهایی مانند Canvas.
- برای صنعت AI: نشاندهنده حرکت گوگل به سمت مدلهای هیبریدی و قابل کنترل است؛ رویکردی که احتمالاً توسط سایر شرکتها نیز دنبال خواهد شد. این مدل همچنین رقابت را در بخش مدلهای کارآمد و مقرونبهصرفه که قابلیتهای پیشرفتهای ارائه میدهند، تشدید میکند.
Gemini 2.5 Flash - سرعت، هوشمندی و کنترل در دستان شما!
گوگل با معرفی Gemini 2.5 Flash، بار دیگر نشان داد که در مرزهای نوآوری هوش مصنوعی حرکت میکند. این مدل با ارائه یک جهش قابل توجه در قابلیتهای استدلال، ضمن حفظ مزایای کلیدی سرعت و هزینه بهینه مدلهای Flash، تعریفی جدید از کارایی ارائه میدهد. قابلیت منحصربهفرد استدلال هیبریدی و بودجه تفکر قابل تنظیم، کنترل بیسابقهای را در اختیار توسعهدهندگان قرار میدهد تا تعادل مورد نظر خود را بین کیفیت، هزینه و سرعت برقرار کنند.
در دسترس قرار گرفتن این مدل هم از طریق API و هم برای عموم کاربران در اپلیکیشن Gemini، نشاندهنده عزم گوگل برای دموکراتیزه کردن دسترسی به هوش مصنوعی پیشرفته و در عین حال کارآمد است. باید دید توسعهدهندگان و کاربران چگونه از این قابلیتهای جدید برای ساخت اپلیکیشنها و تجربیات نوآورانه بهره خواهند برد. های ورت (hiwert.com) به عنوان همراه همیشگی شما در دنیای فناوری، آخرین اخبار و آموزشهای مربوط به استفاده از ابزارهای جدید هوش مصنوعی مانند Gemini 2.5 Flash را از نزدیک دنبال کرده و در اختیار شما قرار خواهد داد. آینده هوش مصنوعی، سریعتر، هوشمندتر و قابل کنترلتر از همیشه به نظر میرسد!



